The Goal:
As the capstone project for EC 710 – Dynamic Programming and Reinforcement Learning, we were tasked with deploying concepts and methods we learned in class. While other projects were more theoretical, analyzing dynamic programming problems in the abstract, I simulated one of the most difficult problems in robotics: bipedal locomotion.
Project Description:
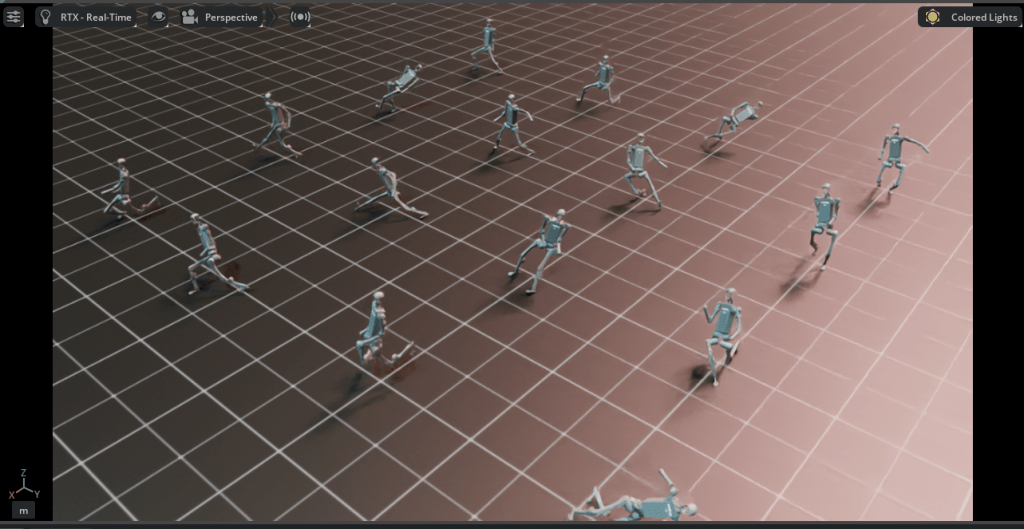
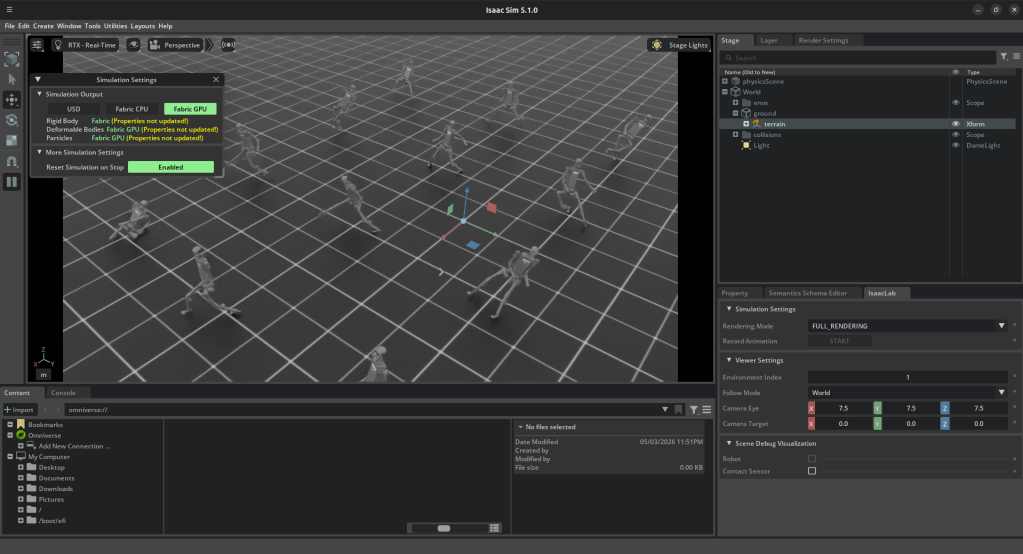
Using Nvidia’s Isaac Lab and Isaac Sim, I trained Unitree’s H1 bipedal robot to walk in a straight line, maintaining its balance as it walked. Due to the time constraints of the project, I chose to restrict the number of terrains the H1 walked on, choosing flat, even terrain to demonstrate the deployment of class concepts.
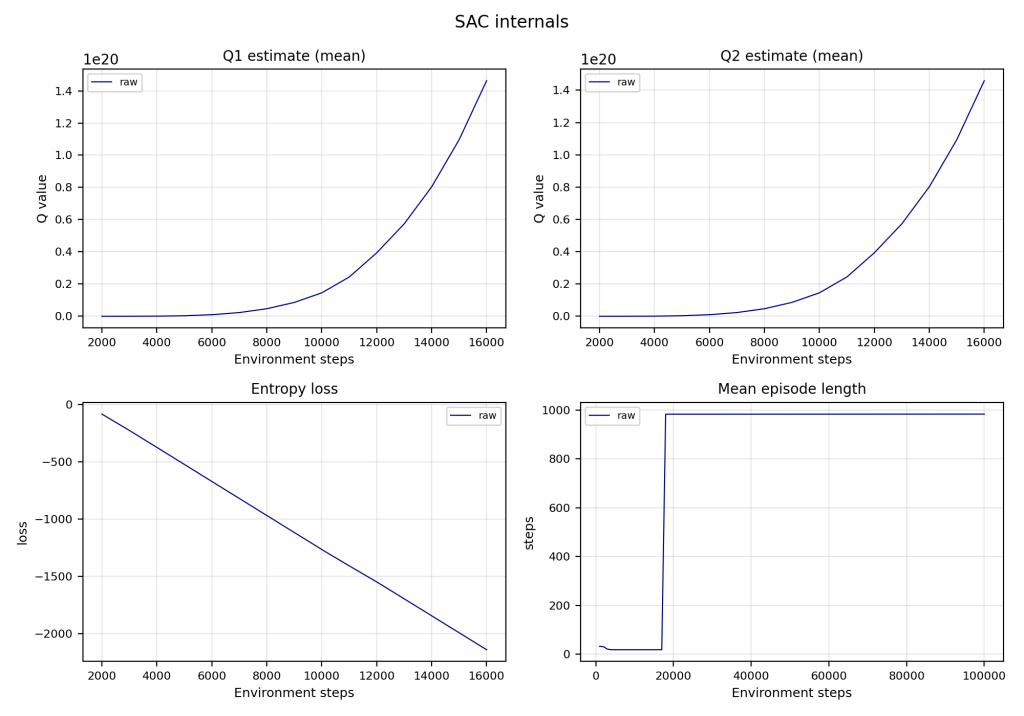
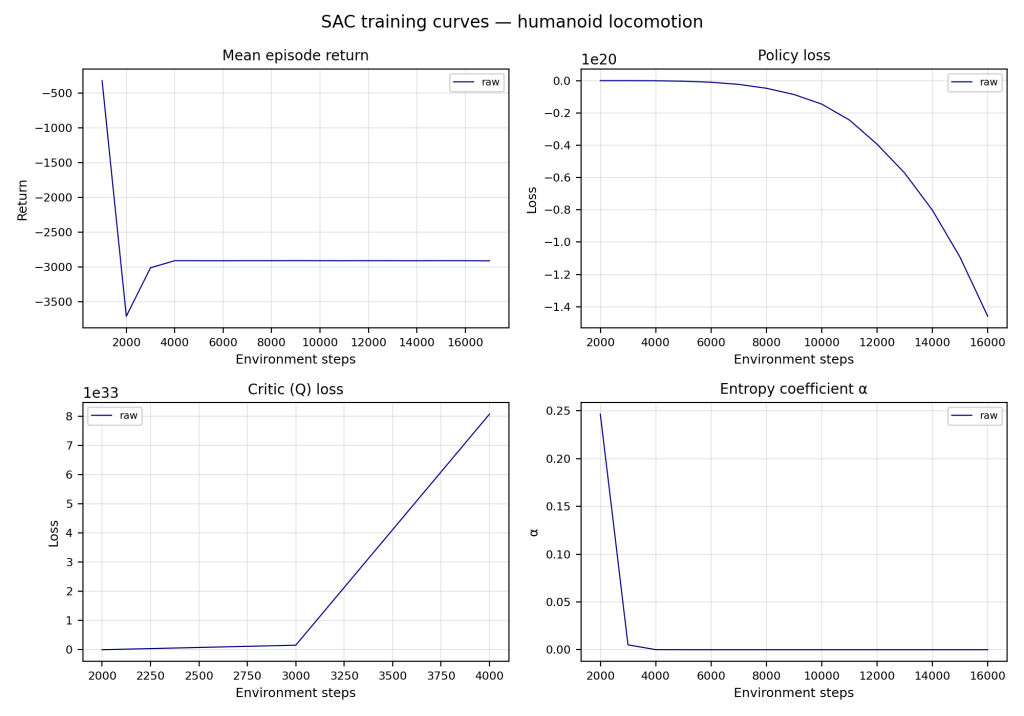
For this project, I primarily used the following concepts: SAC (Soft Actor-Critic) Q-Learning, Infinite Horizon Discounted Cost, and PID control (inherent to the joints of the H1). For the H1, there are 43 state variables and I restricted the number of controls to four: maintaining desired joint position, center of mass balancing, zero moment point control, and maintaining foot contact when applicable.
The project itself has its roots in several key reinforcement learning in simulation papers, the summaries and details of which are in the full project report below.
What went right:
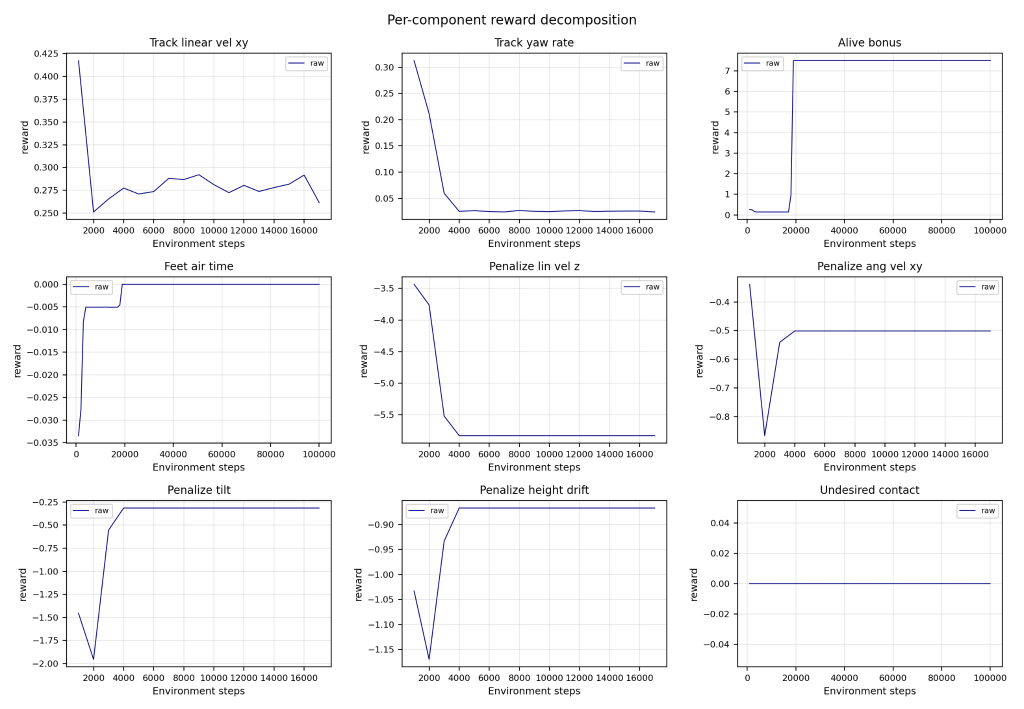
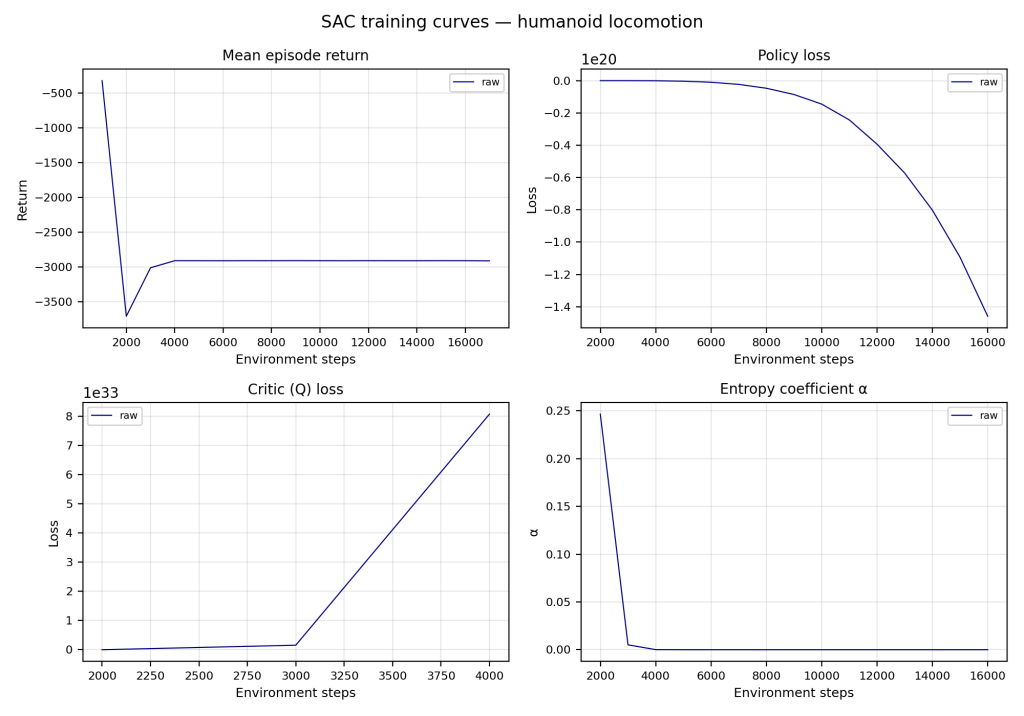
After initial hiccups downloading Isaac Sim and Isaac Lab, training was complete and the H1 robot improved in several performance metrics.
What went wrong:
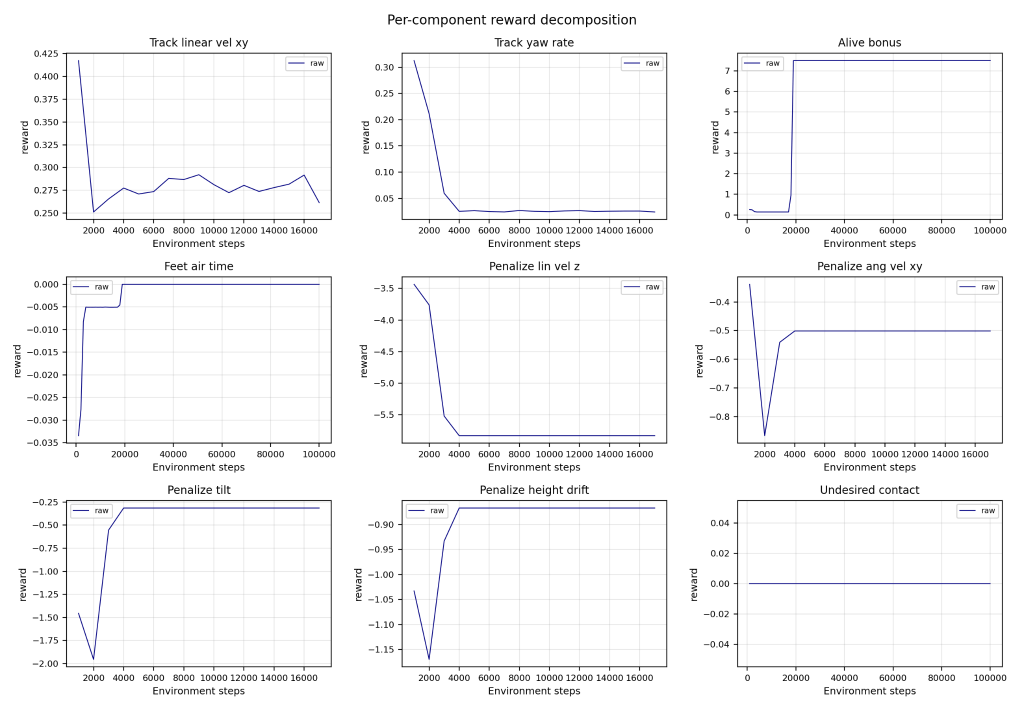
Unfortunately, the H1 robot did not succeed in walking without falling, nor even maintaining balance for more than a few seconds. This is ultimately due to a faulty reward function that emphasized negative actions more than positive ones and caused the robot to be unstable.
Outcome:
Due to the tight time table of this project, I was not ultimately able to tune the reward function and retrain the H1. However, this project inspired future projects to train a robot in simulation and then move it into the real world.
In the coming months I plan to return to this project and properly adjust the reward function and retrain the H1 so that it maintains its balance and eventually introducing more terrain types, like those seen in Rudin et al. (2021).
See the completed report below: