The Goal:
In a team of three people, we investigated the efficacy of Video Language Models (VLMs) for live video navigation. While our intention was for robotic navigation, similar projects deploying this technology are also going into autonomous vehicles and assistive devices for the visually impaired.
Project Description:
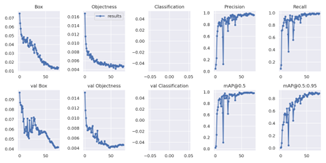
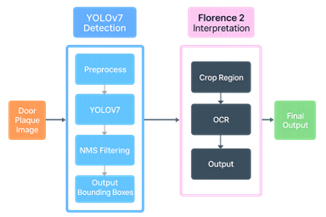
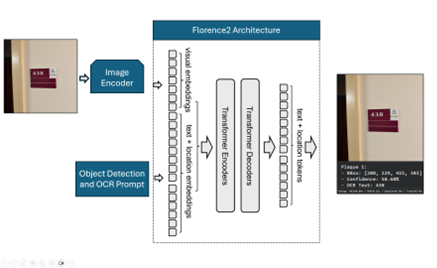
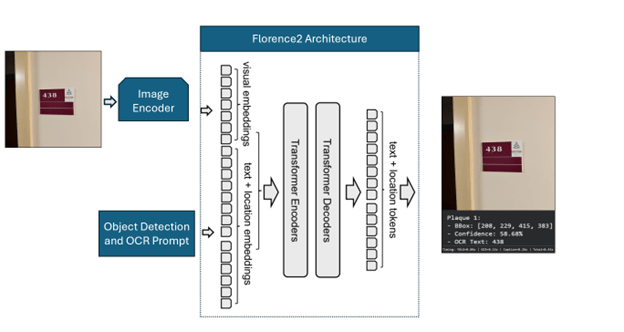
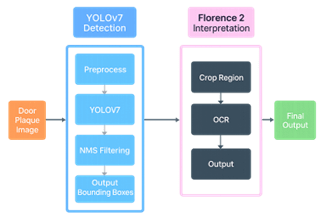
EYES UP is a QLoRA (Quantized Low Rank Adaptation) fine tuned version of Microsoft’s open source VLM Florence2, trained on a custom made and annotated dataset of 813 images. In order to keep our project achievable in our limited time frame, we limited the scope of objects we would fine tune for to room number panels such as you might find at a hotel or a university. We tested the efficacy of using Florence2 in this way by comparing its speed and performance against a combination of the You Only Look Once (YOLO) algorithm to find the door panels and then using Florence2 to perform Object Character Recognition (OCR).
What Went Right:
We were able to fine-tune Florence2 to detect and read the room numbers from the panels, and the combination of YOLOv7 and Florence2 produced similarly positive results.
What Went Wrong:
Quantization of Florence2 in an attempt to make its computation faster was unsuccessful and we were unable to properly fine-tune any quantized version.
Outcome:
Ultimately we learned a lot about VLM architecture as well as the tricky balance of libraries and supported versions. Furthermore, this project gave me experience working with HuggingFace and GitHUB in ways I had not previously experienced.

See the completed report below: