The Goal:
As the capstone project for EC527 – High Performance Programming, we were set with the task to take a common algorithm and write in C both a serial code and at least one optimized code using techniques learned in class, capitalizing on computer and GPU architecture.

Project Description:
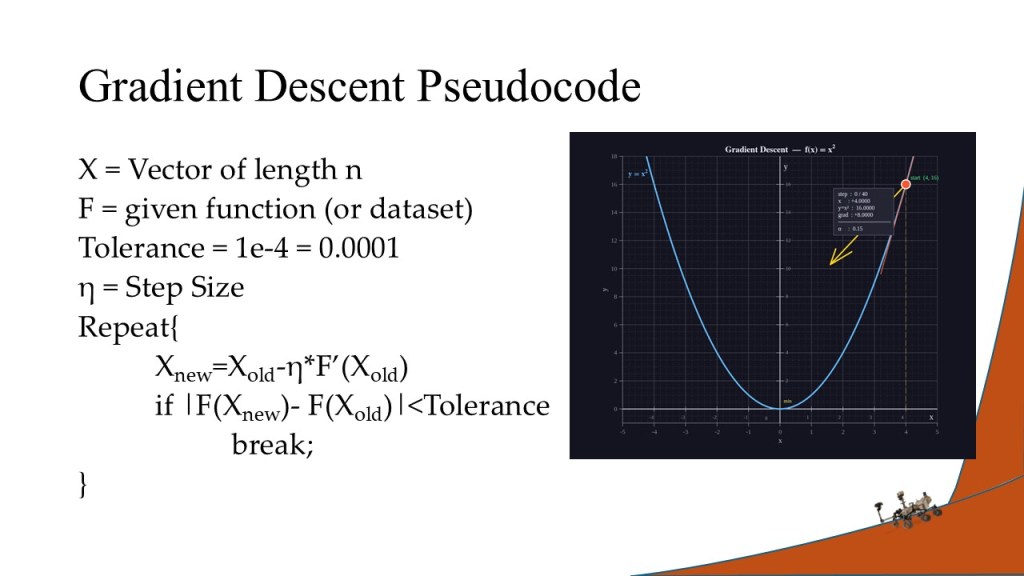
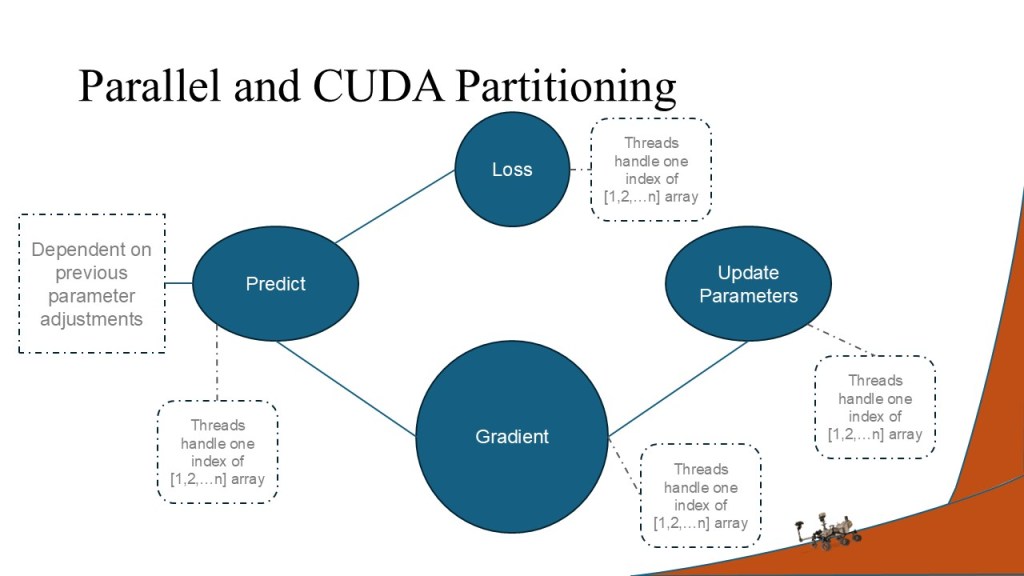
I decided to optimize the gradient descent algorithm, a common and useful optimization algorithm in its own right. For the optimizations, I chose to use OpenMP threading for CPU only optimization and a CUDA optimization to incorporate the GPU. The dataset used was a Martian crater database with recorded crater diameters and depths (the exacts of which can be read in the project report below).
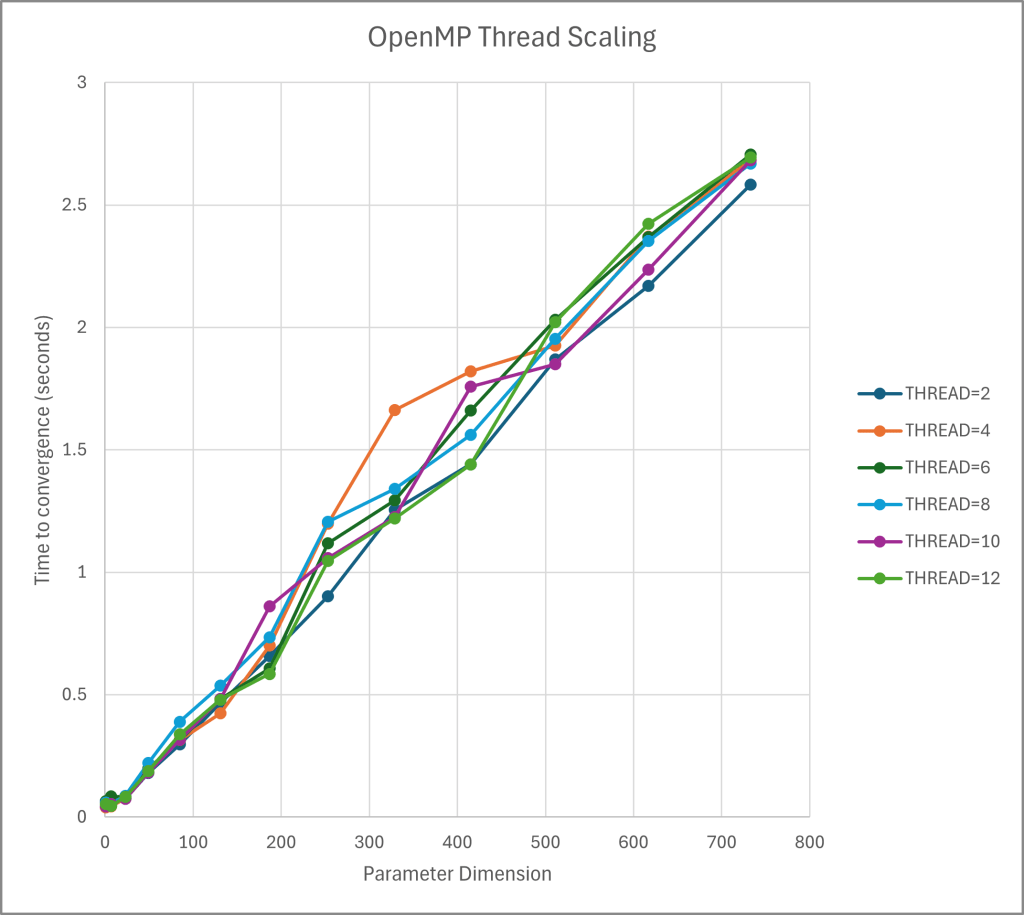
What went right:
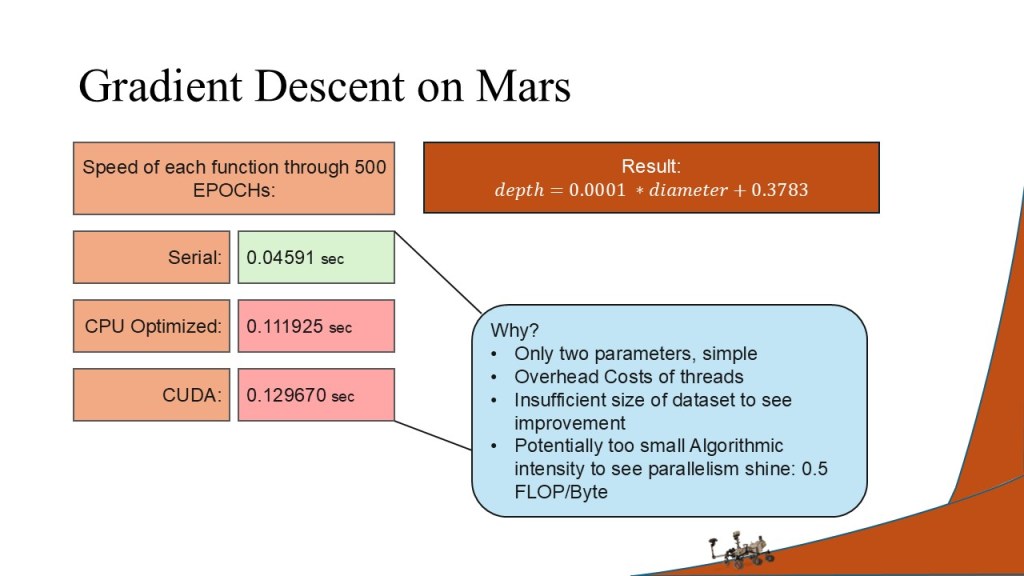
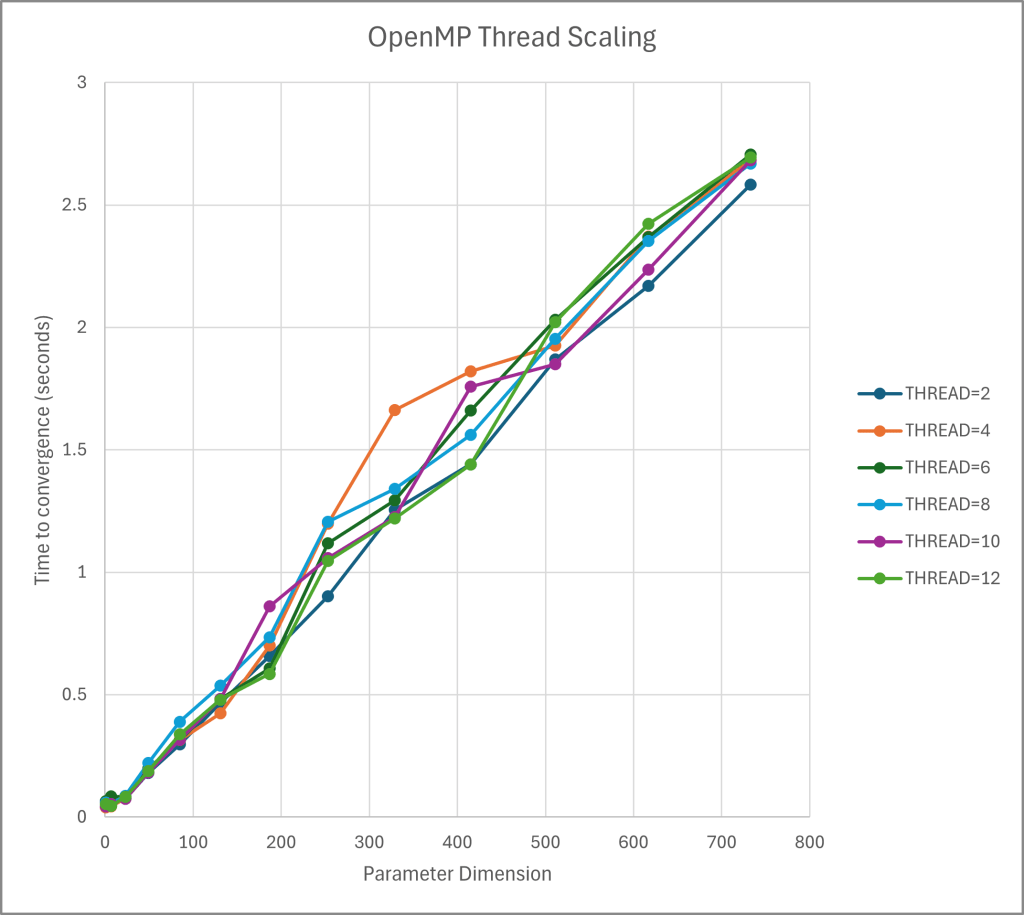
All three scripts (serial, OpenMP, and CUDA) produced valid results and showed the expected optimization of performance over time. The serial version performed better than the optimizations when the dimension optimized over was size 1 due to the overhead performance costs inherent in OpenMP thread assignment and CPU-to-GPU transfer times. However, as the size of the dimensions increased, the time to convergence increased linearly for the serial version, the optimized versions performed increasingly better than the serial version.
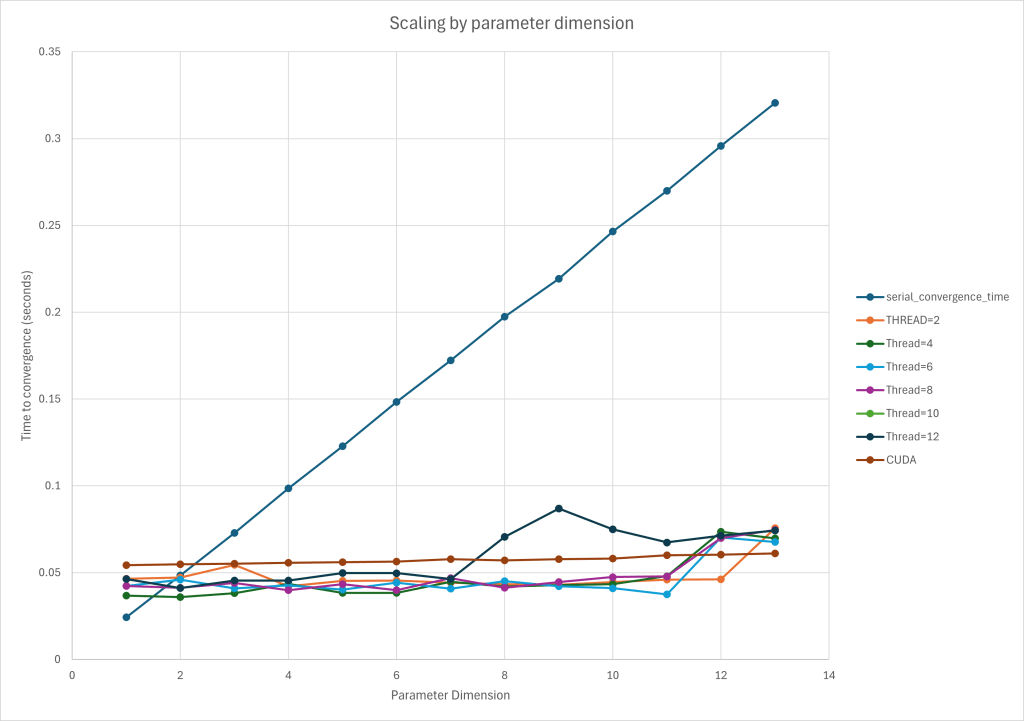
What went wrong:
The relationship between Martian crater depth and diameter is documented (as shown in the report below) but the relationship itself is linear with only one parameter to optimize over. This made scaling difficult.
In order to keep the runs as similar as possible but also to ensure faithful calculations, the crater dataset was used but each increase in dimension was the same calculation performed repeatedly. This allowed for the scaling of dimensionality, while also keeping the frame of reference between versions and dimension sizes the same.
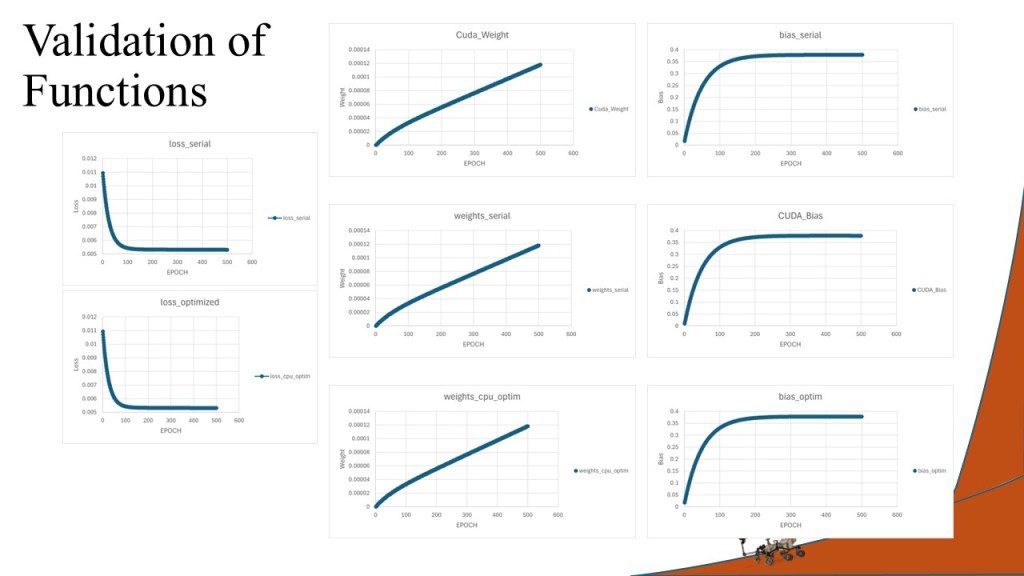
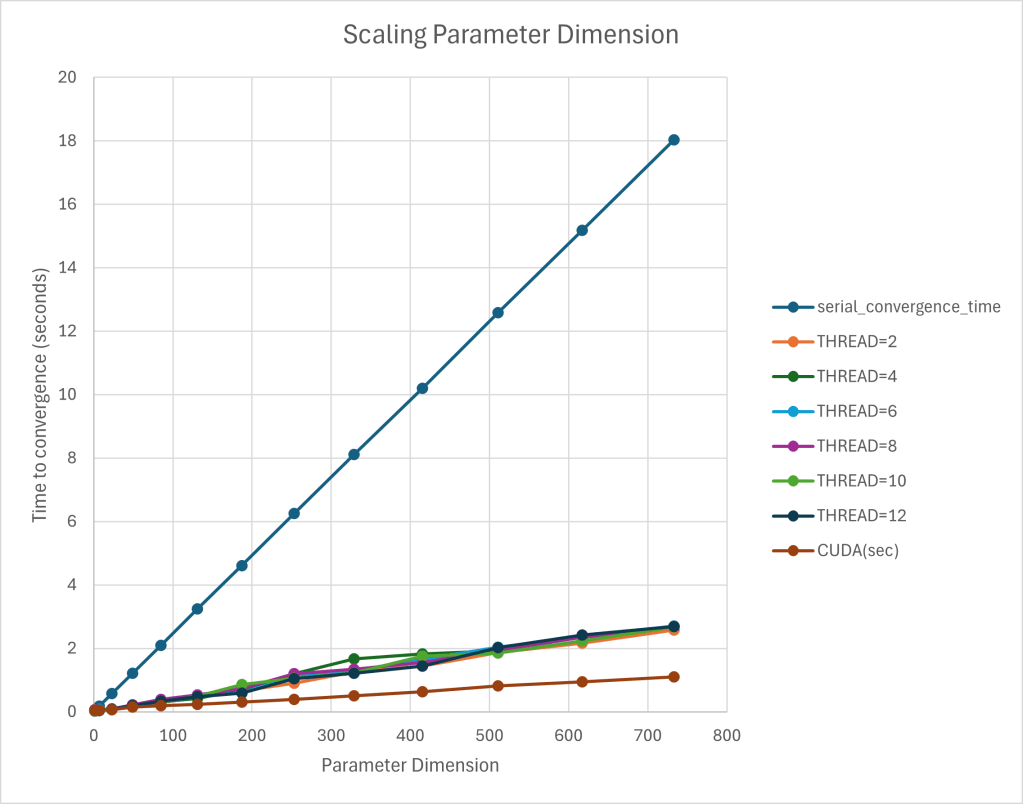
Outcome:
Ultimately, the project was very successful with the results performing as expected. As you can see in the graph on the right, the serial version of the gradient descent function increased linearly with OpenMP being the next best in performance, followed by the GPU’s performance.
Future directions for this project are finding the limit where the GPU takes much longer than it did previously (due to CUDA cache size) and seeing how it compares to performance by OpenMP techniques at the same dimension.
See the completed report below: